Sealed Directories
SeaweedFS Enterprise includes sealed directories, which offload cold, inactive directories out of the filer’s metadata store and into compressed, volume-stored segment chunks — leaving the filer with just the directory entry and a small manifest index. The filer’s metadata store is the practical ceiling on how large a namespace one cluster can hold; since most of a big namespace is usually cold, moving that bulk out of the store lets the same filer hold one to two orders of magnitude more files and directories. On large hash-fanout trees the sealed data’s filer-store footprint drops by roughly 18–58× (see Example savings below).
A seal has two modes. The default, frozen, is fully read-only until unsealed — the right choice for data you know is finished. Mutable seals (-allowUpdates) keep the same metadata savings while still accepting writes: new and changed files land as small overlay records next to the manifest, and a periodic compaction folds them back in automatically, so the directory never has to be taken offline for changes. See Staying writable: mutable seals below.
The filer keeps one metadata record per file and directory. When a dataset grows into the billions of small objects, that metadata store — not the raw data — becomes the scaling limit: it drives filer memory, disk, and backup size. Sealing folds the cold, rarely-changing part of the namespace out of that store and into ordinary volumes, where it is as cheap to keep as any other data (and can be erasure-coded or cloud-tiered).
Why it is needed
Every entry in SeaweedFS costs a metadata record in the filer store (LevelDB, RocksDB, or SQL). That cost is the same whether a file was written a second ago or a decade ago — cold data keeps paying full price:
- Memory and disk pressure on the filer. A namespace of hundreds of millions of entries makes the metadata store large and slow to open, scan, and compact.
- Backups scale with entry count, not activity. Metadata backup and replication carry every cold record, forever.
- Directory listings and lookups slow down as the store grows, even for hot paths, because everything shares one store.
Yet most of that data never changes. Archives, finished experiments, last quarter’s logs, model checkpoints, and the deep leaves of a hash-fanout layout are written once and then only read. Sealing lets you take that cold metadata out of the hot store without moving or re-encoding the data itself.
How it works
When a directory is sealed, its child entries are serialized, zstd-compressed, and written as segment chunks into regular SeaweedFS volumes. The filer replaces the individual child records with a single manifest on the directory entry — a small, sorted index of (first name, last name, chunk) per segment. The original child records are then purged from the store.
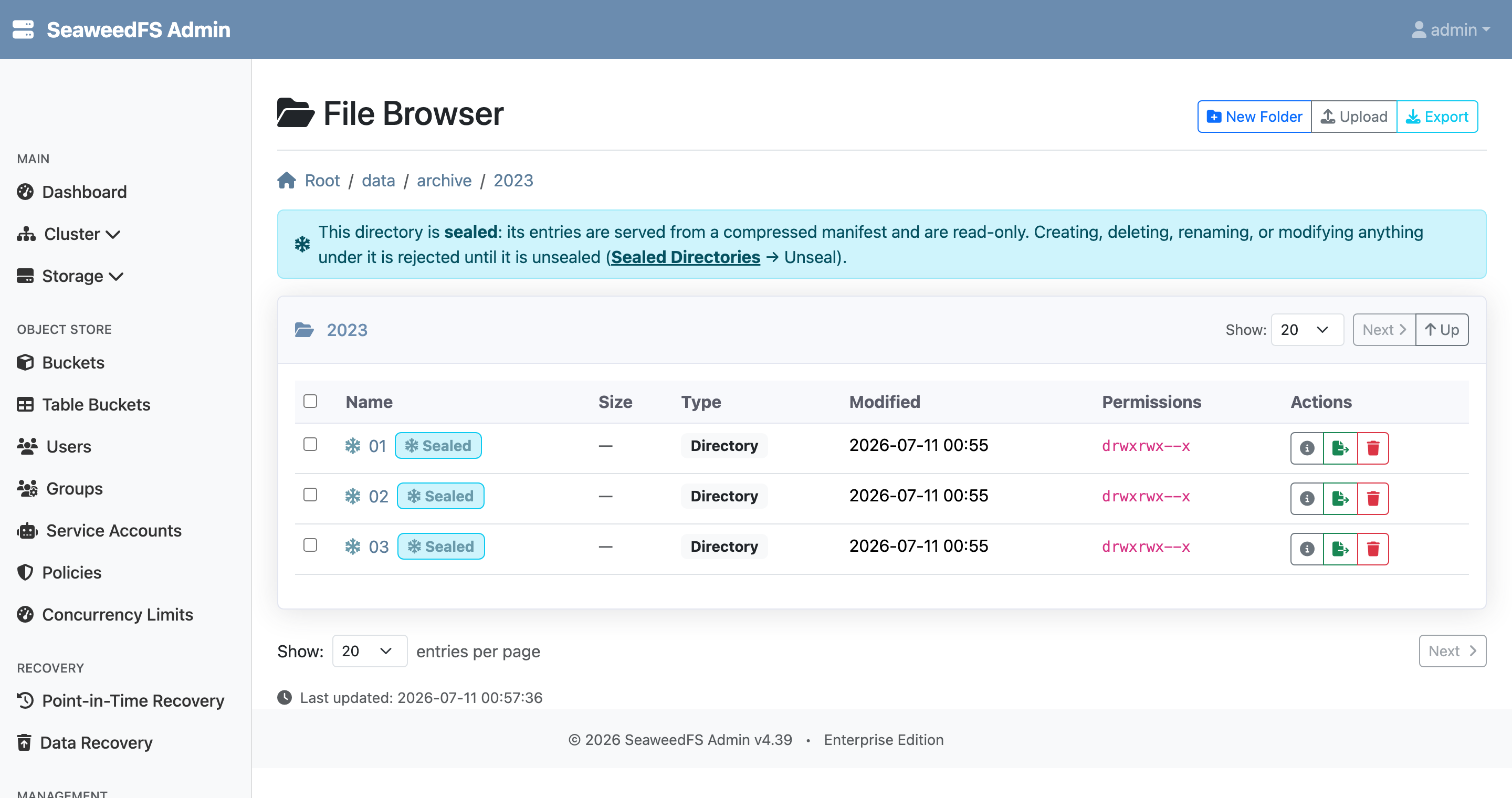
- Reads keep working. Listing or looking up inside a sealed directory is served from the manifest, with the decompressed segments cached in memory. A sealed directory is indistinguishable from a normal one to a reader.
- Writes depend on the mode. A frozen seal rejects every write until the directory is unsealed — the default, for data that has gone cold. A mutable seal admits creates, updates, deletes, and renames instead: they land next to the manifest and a later compaction folds them in.
- The data is just volume data. The segment chunks live in ordinary volumes, so they inherit erasure coding, cloud tiering, and replication like everything else. Sibling directories sealed in one pass share needles, keeping uploads and needle counts low.
- Reversible.
weed shell fs.unseal /pathmaterializes the children back into the filer store, exactly as they were.
Sealing is crash-safe end to end: an evented fence, a build journal, and replay-on-recovery mean a filer (or worker) that dies mid-seal is finished or rolled back automatically, and the change converges across filer peers.
Staying writable: mutable seals
A frozen seal is a one-way door until you unseal — fine for a finished archive, awkward for a directory that gets the occasional straggler write. Mutable seals solve that: seal with -allowUpdates and the directory keeps most of its metadata savings while staying open for business.
- Writes overlay the manifest. A new file, an overwritten one, a delete, or a rename all land as small ordinary metadata records next to the sealed manifest — the bulk of the directory’s history stays packed, and only the recent changes cost a full-size record.
- Compaction folds them back in. Once the overlay grows past a threshold (row count or a percentage of the sealed total — configurable per rule) and the directory has gone quiet again, a compaction pass rewrites the manifest to include the changes and clears the overlay. Compaction is just another seal of the same directory, so it is exactly as crash-safe as the original seal.
- Finding what needs compacting is nearly free. Rather than re-scanning every mutable sealed directory, the
auto_sealworker watches the filer’s own metadata event stream and only looks at directories that actually changed — so the cost of checking scales with how much you’re writing, not with how much you’ve sealed. - You choose per directory or per rule. Seal on demand with
-allowUpdates, or set it in anauto_sealpolicy rule so an entire matching prefix seals mutable automatically. Re-running a seal with a different mode flips it in place — no need to unseal first.
This is the setting for data that’s mostly settled but not entirely done — a dataset still getting occasional corrections, a log directory with rare late-arriving files, a fanout tree where a handful of leaves keep drifting. Fully finished data still wants a frozen seal: it needs no compaction cycles at all and gives the strongest guarantee — a mount client can even cache its listing forever, knowing nothing under it will ever change.
Example savings
How much you save depends on the workload — how much of the tree you seal and how large the directories are. Larger directories amortize the per-manifest overhead better, so they pack more efficiently and reach a higher reduction; a layout of many tiny directories reaches a lower one.
The figures below come from an offline repack of a live cluster’s filer store: 15.77 million entries across 457,795 directories, averaging 62 bytes per entry — a hash-fanout layout dominated by small directories (most hold 10–63 entries).
| What was sealed | Filer-store size for those entries | Residual index kept in the filer store | Reduction |
|---|---|---|---|
| Larger directories only (~6.5% of entries) | 67.3 MiB | 1.2 MiB | ≈58× |
| The whole tree (tiny directories included) | 933.5 MiB | 52.4 MiB | ≈18× |
On this fanout tree, sealing essentially everything shrank the filer store for that data by about 18×; restricting sealing to the larger directories reached about 58× on the portion sealed. Broadly, expect roughly 18–58× less filer metadata for a sealed cold subtree — toward the higher end when directories are large.
Two things to keep in mind about where the data goes:
- The packed child data does not disappear — it moves out of the replicated filer store into ordinary volumes, where it additionally compresses about 4.3–4.8× and can be erasure-coded or cloud-tiered (much cheaper per byte than the filer store).
- Recursive sealing also folds the directory entries themselves into their parents’ manifests, so a fully sealed tree’s residual store cost approaches a single row at the sealed root — the residual figures above are the conservative per-directory bound, so real savings can be higher.
Automatic sealing
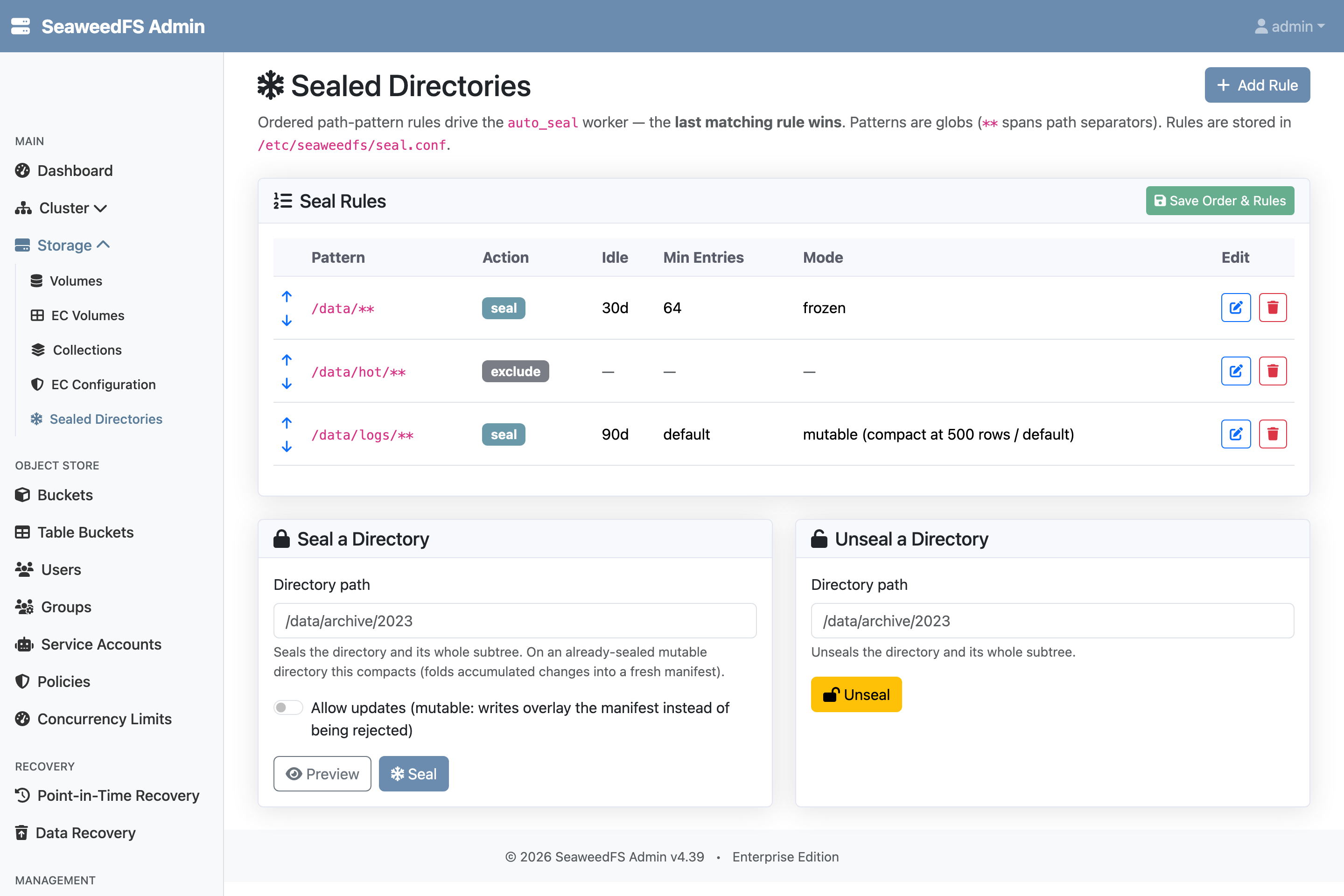
You can seal on demand from the shell or the Admin UI, or make it a standing policy with the auto_seal background worker. Policy is an ordered list of path-pattern rules stored on the filer at /etc/seaweedfs/seal.conf:
{ "rules": [
{ "pattern": "/data/**", "idleSeconds": 2592000, "minEntries": 64 },
{ "pattern": "/data/hot/**", "exclude": true },
{ "pattern": "/data/logs/**", "idleSeconds": 7776000, "allowUpdates": true, "compactMinRows": 500 }
] }
Here everything under /data is sealed frozen once it has been idle for 30 days and has at least 64 entries, /data/hot is never sealed, and /data/logs seals mutable after 90 days idle and re-compacts once 500 changed rows pile up. Rules use gitignore-style globs (** spans separators) and last matching rule wins, so carve-outs and per-subtree thresholds are easy to express. The idle window is measured from the child files’ modification times, so a directory that is still being written is never sealed out from under an active workload.
Managing it
The Admin UI has a Sealed Directories page to edit the rules (including the mode and compaction thresholds), seal or unseal a specific directory on demand (with a dry-run preview), flip a sealed directory’s mode, and trigger a compaction. The file browser marks sealed directories — with a distinct badge for mutable ones — so operators always know what is read-only versus still writable. Metrics report per-operation rejections on frozen directories and the count of committed seals, unseals, mode flips, and compactions.
When to use it
- Very large namespaces where the filer metadata store is the bottleneck — billions of small files, where per-entry metadata dominates memory, disk, and backup size. Offloading the cold bulk lifts that ceiling by one to two orders of magnitude.
- Cold, immutable datasets — archives, completed experiments, aged logs, model checkpoints, or the deep leaves of a hash-fanout tree that are read but never rewritten. Use a frozen seal.
- Mostly-cold datasets that still take the occasional write — a fanout tree with a trickle of late updates, a log directory with rare stragglers. Use a mutable seal so the directory never has to come offline.
- Keeping listings fast — folding cold entries out of the hot store keeps the working set small.
Point the rules at prefixes you know have gone cold (or gone mostly cold), pick frozen for data that is truly finished and mutable for everything else that still needs the occasional write, and unseal anything that turns out to need heavier, ongoing changes.